Table of Contents
Apache Spark
Introduction
Apache Spark is a distributed general-purpose cluster computing system.
Instead of the classic Map Reduce Pipeline, Spark’s central concept is a resilient distributed dataset (RDD) which is operated on with the help of a central driver program making use of the parallel operations and the scheduling and I/O facilities which Spark provides. Transformations on the RDD are executed by the worker nodes in the Spark cluster. The dataset is resilient because Spark automatically handles failures in the Worker nodes by redistributing the work to other nodes.
In the following sections, we give a short introduction on how to prepare a Spark cluster and run applications on it in the Scientific Compute Cluster.
Creating a Spark Cluster on the SCC
We assume that you have access to the HPC system already and are logged in to one of the frontend nodes gwdu101 or gwdu102 .
If that's not the case, please check out our introductory documentation first.
Apache Spark is installed in version 3.4.0, the most recent stable release at the time of this writing. Version 2.4.3 is available as well. The shell environment is prepared by loading the module spark/3.4.0:
gwdu102 ~ > export MODULEPATH=/opt/sw/modules/21.12/scc/common:$MODULEPATH gwdu102 ~ > module load spark/3.4.0
We’re now ready to deploy a Spark cluster. Since the resources of the HPC system are managed by Slurm, the entire setup has to be submitted as a job. This can be conveniently done by running the script scc_spark_deploy.sh, which accepts the same arguments as the sbatch command used to submit generic batch jobs. The default setup is:
#SBATCH --partition fat #SBATCH --time=0-02:00:00 #SBATCH --qos=short #SBATCH --nodes=4 #SBATCH --job-name=Spark #SBATCH --output=scc_spark_job-%j.out #SBATCH --ntasks-per-node=1 #SBATCH --cpus-per-task=24
If you would like to override these default values, you can do so, by handing over the Slurm parameters to the script:
gwdu102 ~ > scc_spark_deploy.sh --nodes=2 --time=02:00:00 Submitted batch job 872699
Especially, if you do not want to share the nodes resources, you need to add --exclusive
In this case, the --nodes parameter has been set to specify a total amount of two worker nodes and --time is used to request a job runtime of two hours. If you would like to set a longer runtime, beside --time, add --qos=normal parameter as well. The job ID is reported back. We can use it to inspect if the job is running yet and if so, on which nodes:
gwdu102 ~ > squeue --jobs=872699
JOBID PARTITION NAME USER ST TIME NODES NODELIST(REASON)
872699 fat-fas Spark ckoehle2 R 1:59 2 dfa[008-009]
The first node reported in the NODELIST column is running the Spark master. Its hostname is used to form a URL like spark://host:port that the spark applications, such as spark-submit and spark-shell need to connect to the master:
gwdu102 ~ > spark-shell --master spark://dfa008:7077
Here, the Spark shell is started on the frontend node gwdu102 and connects to the master dfa008 on the default port 7077.
 Scala code that is entered in this shell and parallelized with Spark will be automatically distributed across all nodes that have been requested initially. N.B.: The port that the application’s web interface is listening on (port
Scala code that is entered in this shell and parallelized with Spark will be automatically distributed across all nodes that have been requested initially. N.B.: The port that the application’s web interface is listening on (port 4040 by default) is also being reported in the startup message.
Once the Spark cluster is not needed anymore, it can be shut down gracefully by using the provided script scc_spark_shutdown.sh and specifying the job ID as an argument:
gwdu102 ~ > scc_spark_shutdown.sh 872699
In case a single node is sufficient, Spark applications can be started inside a Slurm job without previous cluster setup - the --master parameter can be omitted in that case. If you want to quickly test your application on a frontend node or inside an interactive job, this approach is not feasible since by default all available CPU cores are utilized, which would disturb the work other users of the system. However, you can specify the URL local[CORES], where CORES is the amount of cores that the Spark application should utilize to limit your impact on the local system, for example:
gwdu102 ~ > spark-shell --master local[4]
Access and Monitoring
Once your Spark cluster is running, information about the master and workers is being printed to the file scc_spark_job-$JOBID.out in the current working directory you deployed the cluster from. For example, in the case at hand, the MasterUI, a built in web interface that allows us to check the master for connected workers, the resources they provide as well as running applications and the resources they consume, is listening on the master on port 8082.
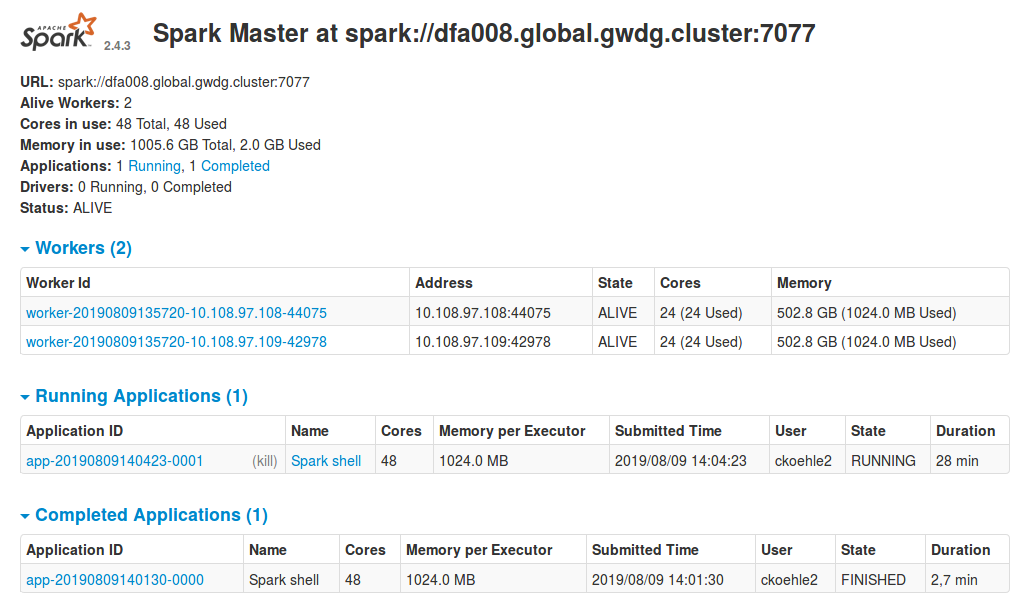
Inside GöNET, an SSH tunnel allows us to open the web interface on localhost:8080 by starting OpenSSH with the following parameters:
ssh -N -L 8080:dfa008:8082 -l ckoehle2 gwdu102.gwdg.de
Example: Approximating Pi
To showcase the capabilities of the Spark cluster set up thus far we enter a short Scala program into the shell we’ve started before.

The local dataset containing the integers from 1 to 1E9 is distributed across the executors using the parallelize function and filtered according to the rule that the random point (x,y) with 0 < x, y < 1 that is being sampled according to a uniform distribution, is inside the unit circle. Consequently, the ratio of the points conforming to this rule to the total number of points approximates the area of one quarter of the unit circle and allows us to extract an estimate for the number Pi in the last line.
Configuration
By default, Spark's scratch space is created in /tmp/$USER/spark. If you find that the 2G size of the partition where this directory is stored is insufficient, you can configure a different directory, for example in the scratch filesystem, for this purpose before deploying your cluster as follows:
export SPARK_LOCAL_DIRS=/scratch/users/$USER